{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Methodology
Методология dataCraft Core включает в себя разбиение процесса обработки данных на 10 этапов (слоёв):
I. Normalize
II. Incremental
III. Join
IV. Combine
V. Hash
VI. Link
VII. Full
VIII. Graph
IX. Attribution
X. Dataset
I. Normalize
Normalize или нормализация - первый слой обработки данных в рамках методологии.
Зачем нужен
На нём происходит подготовка сырых данных для дальнейшей работы.
Обычно сырые данные из Airbyte передаются в хранилище в формате JSON. Пример данных:
{"Date":"2024-03-18","CampaignId":"11102222","CampaignName":"кампания Х","CampaignType":"TEXT_CAMPAIGN","Cost":"13210260000","Impressions":"1750","Clicks":"158"}
На этапе normalize происходит преобразование в более удобный формат - данные извлекаются и распределяются по столбцам, формируется таблица с привычной для пользователей структурой.
Принцип работы
На этом этапе только извлекаем данные из JSON, никаких специальных преобразований не производится.
Зависимости
Поскольку это самый первый этап обработки данных, то зависит только от таблиц, передаваемых из Airbyte в хранилище данных.
Файл модели
Правило наименования
Название файлов модели на этом этапе должно состоять из пяти частей: normalize_{название источника данных}_{название пайплайна}_{название шаблона}_{название стрима}
Ознакомится подробнее с тем, что такое пайплайн, шаблон и стрим в рамках нашей методологии, можно в разделе Terms.
Правило создания
Создаётся один файл на каждую уникальную комбинацию источника данных, шаблона и стрима.
Пример SQL запроса
SELECT
-- извлекаем данные из JSON:
JSONExtractString(_airbyte_data, 'event_receive_datetime') AS __date,
JSONExtractString(_airbyte_data, '__clientName') AS __clientName,
JSONExtractString(_airbyte_data, '__productName') AS __productName,
JSONExtractString(_airbyte_data, 'appmetrica_device_id') AS appmetrica_device_id,
JSONExtractString(_airbyte_data, 'city') AS city,
JSONExtractString(_airbyte_data, 'deeplink_url_parameters') AS deeplink_url_parameters,
JSONExtractString(_airbyte_data, 'event_receive_datetime') AS event_receive_datetime,
JSONExtractString(_airbyte_data, 'google_aid') AS google_aid,
JSONExtractString(_airbyte_data, 'ios_ifa') AS ios_ifa,
JSONExtractString(_airbyte_data, 'os_name') AS os_name,
JSONExtractString(_airbyte_data, 'profile_id') AS profile_id,
JSONExtractString(_airbyte_data, 'publisher_name') AS publisher_name,
-- добавляем технические столбцы:
toLowCardinality(_dbt_source_relation) AS __table_name, -- столбец с названием таблицы, содержащей сырые данные
toDateTime32(substring(toString(_airbyte_extracted_at), 1, 19)) AS __emitted_at, -- столбец с датой выгрузки данных
NOW() AS __normalized_at -- когда была проведена нормализация
-- данные берём из таблицы, которую Airbyte передал в хранилище данных:
FROM ((
SELECT
toLowCardinality(
'datacraft_clientname_raw__stream_appmetrica_default_accountid_deeplinks'
) AS _dbt_source_relation,
toString("_airbyte_raw_id") AS _airbyte_raw_id,
toString("_airbyte_data") AS _airbyte_data,
toString("_airbyte_extracted_at") AS _airbyte_extracted_at
FROM airbyte_internal.datacraft_clientname_raw__stream_appmetrica_default_accountid_deeplinks
))
Правила материализации
В dbt есть такое понятие как материализация (materialization) - то в каком виде будут сохраняться результаты запроса. В данном случае мы не указываем какой-то специальный тип материализации и данные по умолчанию сохраняются как view (представление).
Автоматизация
Статус
В настоящий момент этап нормализации полностью автоматизирован в dataCraft Core.
Макрос
{{ datacraft.normalize() }}
II. Incremental
Incremental или инкрементальный слой обработки данных - второй шаг в рамках нашей методологии.
Зачем нужен
Обновление данных может выполняться двумя способами: полной перезаписью или добавлением новых данных к уже существующим. Это позволяет эффективно обрабатывать большие объёмы информации и снизить нагрузку на систему при обновлении. Выбор между полным и частичным обновлением зависит от типа пайплайна. Для пайплайнов, где данные группируются по дате и/или пользователю/событию, предпочтительнее частичное обновление — добавление новых данных к существующим. Для пайплайнов, где данные группируются по периоду (например, медиаплны) или представляют собой справочники, подходит полная замена данных.
Зависимости
Поскольку это второй этап обработки данных, то он зависит только от таблиц нормализации, полученных на первом шаге normalize.
Файл модели
Правило наименования
Название файлов модели на этом этапе должно состоять из пяти частей: incremental_{название источника данных}_{название пайплайна}_{название шаблона}_{название стрима}
Правило создания
Создаётся один файл, соответственно каждому файлу нормализации.
Пример SQL запроса
Для полной замены данных:
{{ config(
materialized='table',
order_by=('__table_name'),
on_schema_change='fail'
)
}}
SELECT * FROM {{ ref('normalize_appmetrica_registry_default_profiles') }}
Для дозаписи или частичного обновления данных:
{{ config(
materialized='incremental',
order_by=('__date', '__table_name'),
incremental_strategy='delete+insert',
unique_key=['__date', '__table_name'],
on_schema_change='fail'
)
}}
SELECT * FROM {{ ref('normalize_appmetrica_events_default_installations') }}
Правила материализации
Тип материализации зависит типа пайплайна. В dataCraft Core выделяем 4 вида пайплайнов: Events, Datestat, Periodstat, Registry.
- Для Events и Datestat задаём инкрементальный тип материализации (
materialized='incremental'). Инкрементальные модели позволяют dbt вставлять или обновлять записи в таблице с момента последнего запуска этой модели, без необходимости полной перезаписи таблицы. - Для пайплайнов Periodstat и Registry задаётся
materialized='table. В таком случае при каждом запуске модели таблица полностью перезаписывается.
Автоматизация
Статус
В настоящий момент этап инкрементализации полностью автоматизирован в dataCraft Core.
Макрос
{{ datacraft.incremental() }}
III. Join
Join - третий слой обработки данных в рамках методологии dataCraft Core.
Зачем нужен
В рамках этого слоя объединяем в одну таблицу все стримы, которые есть для комбинации “источник+пайплайн”, за исключением пайплайнов registry, относящихся к глобальному подтипу (подробнее см. Pipeline). Например, у AppMetrica для пайплайна events - 5 стримов: deeplinks, events, install, screen_view и sessions_starts. На этом слое все они объединяются в таблицу join_appmetrica_events.
Также на этом слое происходит объединение технических registry с основной таблицей источника. Например, у MyTarget может быть три стрима: 1) banners_statistics, относящийся к пайпалйну datestat; 2) banners и 3) campaigns, относящиеся к техническим registry. В этом случае все три стрима объединяются в одну таблицу join_mt_datestat.
Также на слое Join выполняется первичная предобработка данных: приведение к нужным типам, извлечение значений с помощью регулярных выражений (если нужно), добавление НДС и других бизнес-правил.
Важно, чтобы поля из разных источников, содержащие одни и те же показатели, во всех таблицах назывались одинаково. Поэтому на этом шаге также переименовываем все поля и приводим к единому стандарту. Для нейминга используем стиль camelCase. Пример:
- в
Яндекс.Метрикаполе с id кампании называетсяCampaignId - в
VK Adsполе с id кампании называетсяid
Оба поля нужно переименовать одинаково, в нашем случае какadId.
Ещё одно важное действие на слое Join - добавление новой колонки __link, содержащей название линка, к которому относятся данные (подробнее см. Link). Этот столбец понадобится на этапе Hash.
Принцип работы
Способ объединения таблиц зависит от типа источника данных:
- Например, для
AppMetricaсхожие стримы объединяются в одину таблицу с помощьюUNION ALL. Чтобы объединить таблицы таким способом, поля содержащие одни те же показатели, должны называться одинаково, а количество столбцов должно быть равным и они должны располагаться в одинаковом порядке. - Стримы других источников, например,
VK AdsилиMyTarget, объединяются с помощьюJOINпо общему полю, например,idкампании.
Если у комбинации источник+пайплайн только один стрим или данные относятся к пайплайну Registry глобального подтипа, то на этом шаге проводится только предобработка данных и приведение названий столбцов к единому стандарту.
Перед переименованием полей в разных источниках необходимо составить справочник стандартных названий.
Зависимости
Зависит от всех таблиц слоя Incremental, относящихся к одному источнику и пайплайну (исключение объединение с техническими registry, в этом случае зависит от всех таблиц слоя Incremental, относящихся к одному источнику и пайплайну, плюс от таблиц Incremental, относящихся к техническим registry.
Файл модели
Правило наименования
- Для всех пайплайнов, кроме глобальных
Registry, название состоит из трёх частей:
join_{название источника}_{название пайплайна}. - Для глобальных
Registryназвание формируется следующим образом:
join_{название источника}_{название пайплайна}_{название линка}
Правило создания
Создаётся один файл на каждую комбинацию источник+пайплайн. Исключение пайплайн Registry глобального подтипа. В этом случае создаётся модель на каждую комбинацию источник+пайплайн+линк.
Пример SQL запроса
{{ config(
materialized='incremental',
order_by=('__date', '__table_name'),
incremental_strategy='delete+insert',
unique_key=['__date', '__table_name'],
on_schema_change='fail'
) }}
-- для каждого стрима создаём его CTE с одинаковым набором полей и их расположением
-- первый стрим - deeplinks
WITH join_appmetrica_events_deeplinks AS (
SELECT
toDateTime(__date) AS __date,
toLowCardinality(__table_name) AS __table_name,
toDateTime(event_datetime) AS event_datetime,
toLowCardinality(splitByChar('_', __table_name)[6]) AS accountName,
appmetrica_device_id AS appmetricaDeviceId,
assumeNotNull(COALESCE(nullIf(google_aid, ''), nullIf(ios_ifa, ''), appmetrica_device_id, '')) AS mobileAdsId,
profile_id AS crmUserId,
'' AS visitId,
'' AS clientId,
'' AS promoCode,
os_name AS osName,
city AS cityName,
assumeNotNull(coalesce({{ datacraft.get_adsourcedirty() }}, publisher_name, '')) AS adSourceDirty,
<...>
0 AS installs,
'' AS installationDeviceId,
__emitted_at,
toLowCardinality('AppDeeplinkStat') AS __link
FROM {{ ref('incremental_appmetrica_events_default_deeplinks') }}
)
<...>
-- пятый стрим - sessions_starts
, join_appmetrica_events_sessions_starts AS (
SELECT
<...>
FROM {{ ref('incremental_appmetrica_events_default_sessions_starts') }}
)
-- теперь делаем UNION записанных ранее CTE
, final_union AS (
SELECT *
FROM join_appmetrica_events_deeplinks
UNION ALL
SELECT *
FROM join_appmetrica_events_events
UNION ALL
SELECT *
FROM join_appmetrica_events_install
UNION ALL
SELECT *
FROM join_appmetrica_events_screen_view
UNION ALL
SELECT *
FROM join_appmetrica_events_sessions_starts
)
SELECT *
FROM final_union
Правила материализации
Для всех join таблиц тип материализации 'view'.
Автоматизация
Статус
В настоящий момент этап `Join' полностью автоматизирован в dataCraft Core.
Макрос
{{ datacraft.join() }}
IV. Combine
Combine или объединение - четвертый слой обработки данных в рамках методологии.
Зачем нужен
На этом слое происходит объединение всех одинаковых пайплайнов. Позволяет собрать данные их разных источников вместе.
Например, пайплайн 'events' есть у двух источников - Яндекс.Метрика и AppMetrica. Следовательно, данные по событиям из этих двух источников можем объединяем в одну таблицу.
Принцип работы
Поскольку на этапе Join мы подготовили наши данные и переименовали одинаково столбцы в разных источника, то объединение сводится к простому UNION ALL всех таблиц с одинаковым пайплайном. Если каких-то столбцов не хватает в одной из таблиц, то создаётся столбец
- либо с пустыми значениями:
'' as utmSource - либо с нулевыми:
0 AS sales
Исключение составляют таблицы, относящиеся к пайплайну Registry глобального подтипа.
Зависимости
Зависит от таблиц слоя Join c одинаковыми пайплайнами. В случае Registry глобального подтипа от таблиц слоя Join с одинаковой комбинацией пайпланй+линк.
Файл модели
Правило наименования
Название файлов модели формируется так:
combine_{название пайплайна}- для всех пайплайнов, кромеRegistryглобального подтипаcombine_{название пайплайна}_{название линка}- дляRegistryглобального подтипа
Правило создания
Создаётся один файл для каждого пайплайна. В случае пайплайна Registry для каждой комбинации пайплайн+линк.
Пример SQL запроса
{{ config(
materialized='incremental',
order_by=('__date', '__table_name'),
incremental_strategy='delete+insert',
unique_key=['__date', '__table_name'],
on_schema_change='fail'
)
}}
WITH all_events AS (
SELECT *
FROM {{ ref('join_appmetrica_events') }}
UNION ALL
SELECT *
FROM {{ ref('join_ym_events') }}
)
SELECT *
FROM all_events
В случае пайпалйна Registry, если существует только одна комбинация пайплайн+линк, запрос сводится к простому селекту:
{{ config(
materialized='table',
order_by=('__table_name'),
on_schema_change='fail'
)
}}
SELECT * FROM {{ ref(join_источник_registry_линк) }}
А если комбинация пайплайн+линк есть в ещё каком-то источнике, то:
{{ config(
materialized='table',
order_by=('__table_name'),
on_schema_change='fail'
)
}}
SELECT * FROM {{ ref(join_источник_registry_линк) }}
UNION ALL
SELECT * FROM {{ ref(join_другойисточник_registry_линк) }}
Правила материализации
Если данные относятся к пайплайнам datestat или events используем инкрементальный тип материализации: materialized='incremental'.
В остальных случаях: materialized='table'.
Автоматизация
Статус
В настоящий момент этап combine полностью автоматизирован в dataCraft Core.
.
Макрос
{{ datacraft.combine() }}
V. Hash
Hash или слой хэширования данных - пятый шаг в рамках нашей методологии.
Hash (хэш) - это уникальный ключ, который рассчитывается как функция бизнес-ключа. Бизнес-ключ, в свою очередь, - это комбинация одного или нескольких полей, по которым можно уникально идентифицировать запись в датасете. В отличии от бизнес-ключа, хэш всегда имеет одинаковую длину и с ним удобнее работать.
Зачем нужен
На этом слое происходит добавление к данным столбцов, содержащих хэши. Хэши необходимы на следующих этапах работы с данными:
- для удаления дубликатов на слое
Link - для джойна с справочниками на слое
Full - для графовой склейки на слое
Graph.
Принцип работы
Процесс формирования бизнес-ключа и затем хэша включает несколько этапов.
- Сначала нужно определить из каких полей состоит бизнес-ключ. В dataCraft Core используется специальный файл -
metadata.sql. В нём описываются все сущности в данных и какие поля уникально их идентифицируют, а также какие сущности к каким Link|линкам относятся. Пример метадаты можно посмотреть тут. - Далее необходимо подготовить поля из которых формируется бизнес-ключ: применить все технические преобразования, привести строки к верхнему регистру, чтобы из-за разницы в регистре не менялся хэш, объединить все компоненты бизнес-ключа через разделитель.
- И уже на основе этого подготовленного бизнес-ключа получается хэш с помощью специальной хэш-функции. В dataCraft Core используем
MD5.
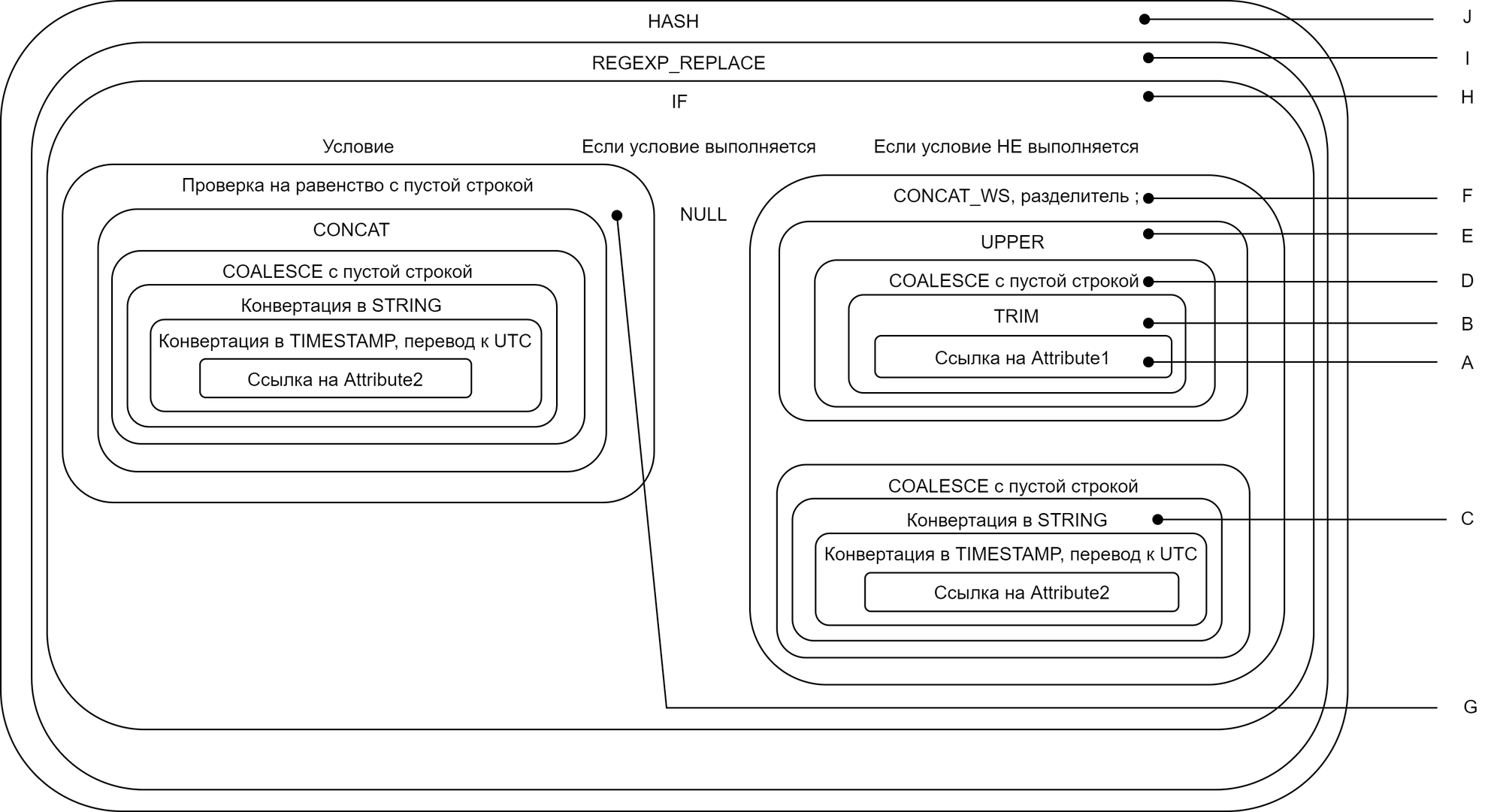
Схематично получение хэша можно представить следующим образом:

*Каждый прямоугольник на схеме обозначает отдельную функцию.
Специальный макрос с помощью metadata.sql и колонки __link отбирает поля, необходимые для формирования бизнес-ключа, производит все необходимые преобразования и формирует поля с хэшами. В методологии dataCraft Core выделяется две группы хэшей:
- хэши для линков. Эти хэши рассчитываются только на основе
main_entities(см. Link ) и являются основными хэшами. По ним проводится дедупликация данных на следующем слое. Для формирования этой группы хэшей в основном макросе используется дополнительный -link_hash(). Колонка, содержащая эти хэши, называется__id. - вторая группа - это хэши по сущностям. В этом случае можно выделить две подгруппы:
2.1 хэши по сущностям, по которым можно идентифицировать пользователя (например, номер телефона). В метадате такие сущности помечены меткойglue: yes. Эти хэши необходимы для графовой склейки.
2.2 хэши по сущностям, по которым можно сделатьJOINмежду разными пайплайнами. Например, соединить данные по событиям (пайплайнEvents) с каким-то справочником (пайплайнRegistry). В этом случае хэш будет формироваться на основе пересекающихся сущностей, то есть если в одном линке сущность изmain_entitiesилиother_entitiesвходитmain_entitiesкакого-то другого линка, относящегося к пайплану Registry, то создаётся хэш для данной сущности в табличкеhash_{название первого линка}.
Вторая группа - дополнительные хэши, которые не всегда необходимы. Они используются на этапах, которые идут после слоя Link. Для формирования хэшей по сущностям, внутри основного макроса, используется макрос entity_hash().
Зависимости
Зависит от таблиц с соответствующим пайплайном, полученных на этапе Combine. Для глобальных Registry зависит от таблицы с соответствующей комбинацией пайплайн+линк.
Файл модели
Правило наименования
Название файлов модели на этом этапе:
hash_{название_пайплайна}- для всех пайплайнов, кромеRegistryhash_{название_пайплайна}_{линк}- дляRegistryглобального подтипа.
Правило создания
Для всех пайплайнов, кроме Registry, создаётся один файл, соответственно каждому файлу слоя Combine. Так как на слое Combine происходит объединение всех данных в рамках одного пайплайна, получается одна модель Hash на каждый пайплайн.
Для пайплайна Registry создаются модели для всех комбинаций пайплайн+линк.
Пример SQL запроса
(в упрощённом виде и без использования основного макроса)
{{ config(
materialized='table',
order_by=('__table_name'),
on_schema_change='fail'
)
}}
{% set metadata = fromyaml(metadata()) %}
SELECT
*,
{{ link_hash('MediaplanStat', metadata) }},
{{ entity_hash('UtmHash', metadata) }}
FROM {{ ref('combine_periodstat') }}
Правила материализации
Зависит от типа пайплайна:
- для пайплайнов
EventsиDatestat- инкрементальный тип. Инкрементальность идет по тем же полям, что и на слоеIncremental- по дате. - для пайплайнов
Periodstat,Registry инрементальности нет, в этом случае данные материализуются как'table'
Автоматизация
Статус
В настоящий момент в dataCraft Core этап хэширования полностью автоматизирован.
Макрос
{{ datacraft.hash() }}
VI. Link
Link - шестой слой обработки данных. Если дополнительных преобразований не требуется, то данный слой является последним.
Зачем нужен
На этом слое происходит дедупликация данных. В link-таблицы попадают только уникальные строки.
Принцип работы
Дедупликация проводится c помощью хэшей, которые были получены на прошлом слое. Принцип сохранения строк - оставляем уникальные строки:
- по комбинации хэша и поля
__dateдля пайплайнов с инкрементальным типом материализации (EventsиDatestat) - просто по хэшу там, где инкрементальности нет (пайплайны
RegistryиPeriodstat) Данные группируются по значениям хэшей и выбирается максимальное значение для нечисловых полей и сумма (или другая агрегация) для численных полей.
Зависимости
Зависит от таблиц с соответствующим пайплайном, полученных на слое Hash. Для пайплайна Registry - от с сответствующей комбинацией пайплайн+линк.
Файл модели
Правило наименования
- Для всех пайплайнов, кроме
Registry, название моделей на этом слое формируется из двух частей:link_{название пайплайна}. - Для
Registryглобального подтипа:link_{название_пайплайна}_{линк}.
Правило создания
Создаётся по одной модели на каждую модель слоя Hash.
Пример SQL запроса
(без использования макроса)
{{ config(
materialized='table'
)
}}
SELECT MAX(accountName) AS accountName,
<...>
SUM(adCost) AS adCost,
SUM(impressions) AS impressions,
SUM(clicks) AS clicks
FROM {{ ref('hash_datestat') }}
GROUP BY __id
Правила материализации
Правило материализации аналогично предыдущему слою:
- для наборов данных, относящихся к пайплайнам
EventsиDatestat, используется инкрементализация:materialized='incremental' - для всех остальных - материализация без инкрементализации с полной перезаписью:
materialized='table'
Автоматизация
Статус
В настоящий момент в dataCraft Core этап дедупликации полностью автоматизирован.
Макрос
{{ datacraft.link() }}
VII. Full
Зачем нужен
Данный слой необходим для объединения данных со справочниками или данных из разных пайплайнов в единую таблицу.
Помимо этого, в зависимости от задачи, на этом слое можно добавлять поля или проводить дополнительную обработку строк.
Если никаких объединений и преобразований не производится, то этот слой всё равно реализуется, чтобы настроить материализацию.
Принцип работы
Преобразования и с чем объединяются link-таблици зависит от пайплайна:
- для
Events- производитсяJOINсо всеми доступными справочниками (пайплайнRegistry) и добавляться полеqidиз графовых таблиц (см. VIII. Graph). - для
Datestat- толькоJOINсо справочниками (пайплайнRegistry) - для
Periodstat- приджойниватьсяRegistryи данные разбиваются по датам между первой и последней датой периода
Для джойна используются хэши, полученные на слое Hash по сущностям (см. V. Hash). При объединении, обычно, левой таблицей является линк-таблица, а справочник - правой, и используется LEFT JOIN. Это необходимо для того, чтобы не потерять данные из основной таблицы в случае, если в справочнике нет какой-то информации, которая есть в основной линк-таблице.
Для пайплайна Registry full-таблицы не создаются.
Зависимости
Зависит от таблиц, полученных на слое Link. Исключение пайплайн Events. Он также зависит от таблицы graph_qid, получаемой на слое Graph.
Файл модели
Правило наименования
Название файлов модели на этом этапе состоит из двух частей: full_{название пайплайн}
Правило создания
Создаётся один файл для каждого пайплайна. Исключение таблицы-справочник пайплайна Registry. Для них отдельный файл не создаётся, так как они присоединяются к основным данным из других пайплайнов.
Пример SQL запроса
Если никаких преобразований и объединений не производим, то запрос сводится к простому селекту:
{{
config(
materialized = 'table',
order_by = ('__datetime')
)
}}
SELECT
*
FROM {{ ref('link_events') }}
В случае с объединением со справочником запрос выглядел бы так:
{{
config(
materialized = 'table',
order_by = ('__datetime')
)
}}
WITH link_events AS (SELECT *
FROM {{ ref('link_events') }}),
link_registry AS (SELECT *
FROM {{ ref('link_registry') }})
SELECT * FROM link_events as t1
LEFT JOIN link_registry as t2 USING(utmHashHash)
Правила материализации
Для всех пайплайнов, кроме Datestat, материализация на этом слое - 'table'. Для Datestat используем инкрементальный тип материализации: materialized='incremental'.
Автоматизация
Статус
Этап Full полностью автоматизирован.
Макрос
{{ datacraft.full() }}
Следующие два слоя graph и attribution в основном используются для маркетинговой аналитики.
VIII. Graph
Graph или слой графовой склейки.
Зачем нужен
На слое Link мы очистили данные от явных дубликатов, но проблема дублирования может возникать и на более высоком уровне. Данные могут иметь аккуратные однотипные идентификаторы, но при этом одному и тому же реальному объекту может соответствовать несколько бизнес-ключей. Рассмотрим пример с данными из CRM-системы. Может получится так, что на одного и того же клиента заведено две (или более) карточки. Такое может произойти, если, например, у клиента несколько номеров телефона. Обычно, если в компанию поступает звонок от клиента с неизвестного номера, у него спрашивают, обращался ли он ранее. Если он говорит, что обращался, в имеющуюся карточку добавляют новый номер. Если нет, то создают новую карточку. Клиент не обязан отвечать правду и помнить свои прошлые обращения. Возникает дублирование данных по одному и тому же клиенту.
Слой Graph нужен для того, чтобы объединить все данные по одному пользователю/объекту, у которого есть различные идентификаторы, как, например, в примере с разными номерам телефона, но нет фиксированного id.
Принцип работы
Для объединения всех данных по одному объекту используется графовая склейка. Граф - это множество вершин (узлов, node) и ребер (взаимосвязей, edge). Если вернуться к примеру с номерами телефонов и карточками в CRM-системе, карточки и номера телефонов будут является вершинами (узлами), а связи между ними - рёбрами.
Упрощённо алгоритм графовой склейки для нахождения дублей можно описать так:
- Находим все группы вершин, связанные между собой с помощью ребер. То есть в одну такую группу входят все вершины, между которыми можно перемещаться, проходя по одному или нескольким ребрам. Такие группы называются свя́зными компонентами графа.
- Все вершины одной связной компоненты считаем относящимися к одному и тому же объекту. Если в группе находятся несколько идентификаторов объекта — они являются дублями.
Реализация графовой склейки в dataCraft Core разбита на 6 подэтапов. Каждый подэтап реализуется с помощью отдельного макроса:
-
graph_tuples: задача этого макроса составить на основе данных из link-таблицы иmetadata.sqlтаблицу соответствия из двух колонок. В первой колонкеhashсодержится кортеж (tuple) из трех элементов:- название линка (колонка
__link) (например,AppInstallStat) - дата и время
- главный хэш (
__id)
Во второй колонкеnode_left- данные по которым можно идентифицировать пользователя. Эта колонка также является кортежем из трёх элементов: - название колонки, например:
crmUserHash(в файлеmetadata.sqlсущности, по которым можно идентифицировать пользователя, имеют меткуglue: yes) - дата и время (если есть, либо нулевая дата:
toDateTime(0)) - собственно содержание строки (сам хэш
crmUserHash)
Рассмотрим суть этой таблицы на примере: для
AppInstallStatглавный хэш рассчитается поAccountAppMetricaDeviceMobileAdsIdCrmUserOsNameCityAdSourceUtmParamsUtmHash
Может быть, например, так, что у одного
CrmUserнесколькоAppMetricaDevice, например три, тогда для этого пользователя будет три разных главных хэша__id. В этом случае в колонкеnode_leftбудет три строчки с одинаковым содержанием и им будет соответствовать три строчки в колонкеhashc разными кортежами.В
matadata.sqlмы описываем модель склейки - какие колонки нужны для неё. В таблице, которую получаем с помощью этого макроса, содержатся все возможные комбинации между содержимым этих колонок. - название линка (колонка
-
graph_lookup: этот макрос формирует список уникальныхhashиnode_leftи присваивает каждому номер -key_number. Необходимо для экономии памяти, так как содержимое колонок таблицы подслояgraph_tuplesзанимает довольно большой объём. То есть создаётся своего рада справочник. Далее, вместоhashиnode_left, будем использовать их номера в качестве идентификатора. Уникальные значенияhashиnode_leftзаписываются в колонкуkay_hash. -
graph_unique: содержит те же данные, что и подслойgraph_lookup. Отличие - порядок сортировки. Вgraph_lookupв таблицу записываем данные отсортированные по возрастаниюkey_number, а вgraph_unique- поkay_hashв алфавитном порядке. Необходимо для удобства дальнейшей обработки. -
graph_edge: заменяем в таблицеgraph_tuplesкортежи (таплы) наkey_numberс помощью джойнов. Переименовываем колонки:hashиnode_leftназываемnode_id_rightиnode_id_leftсоответственно. Плюс добавляем дополнительные колонки:group_id(дублирует колонкуnode_id_left)has_changed- содержит единицу, служебное поле
Эти две колонки будут нужны для работы алгоритма графовой склейки. Также после выполнения основного запроса, с помощьюpost_hook, меняем местами содержимое колонокnode_id_rightиnode_id_left.
-
graph_glue: с помощью этого макроса и дополнительногоcalc_graphреализуется склейка. Представляет собой цикл, в котором последовательно джойним таблицу, которую получили на подэтапеgraph_eage, саму с собой сначала используя в качестве ключаnode_id_left, а затемnode_id_right. Как это происходит:- 5.1 Сначала группируем данные из
graph_eageпоnode_id_leftи вычисляем минимальный id группы:min(group_id) as min_group_id. (помним, что мы поменяли местами содержимое столбцовnode_id_leftиnode_id_rightна прошлом шаге, а столбецgroup_idсодержит значения исходногоnode_id_left). - 5.2 Затем производим джойн таблицы, которую получили на шаге 5.1 с таблицей
graph_eageпоnode_id_left. - 5.3 Повторяем тоже самое для
node_id_right
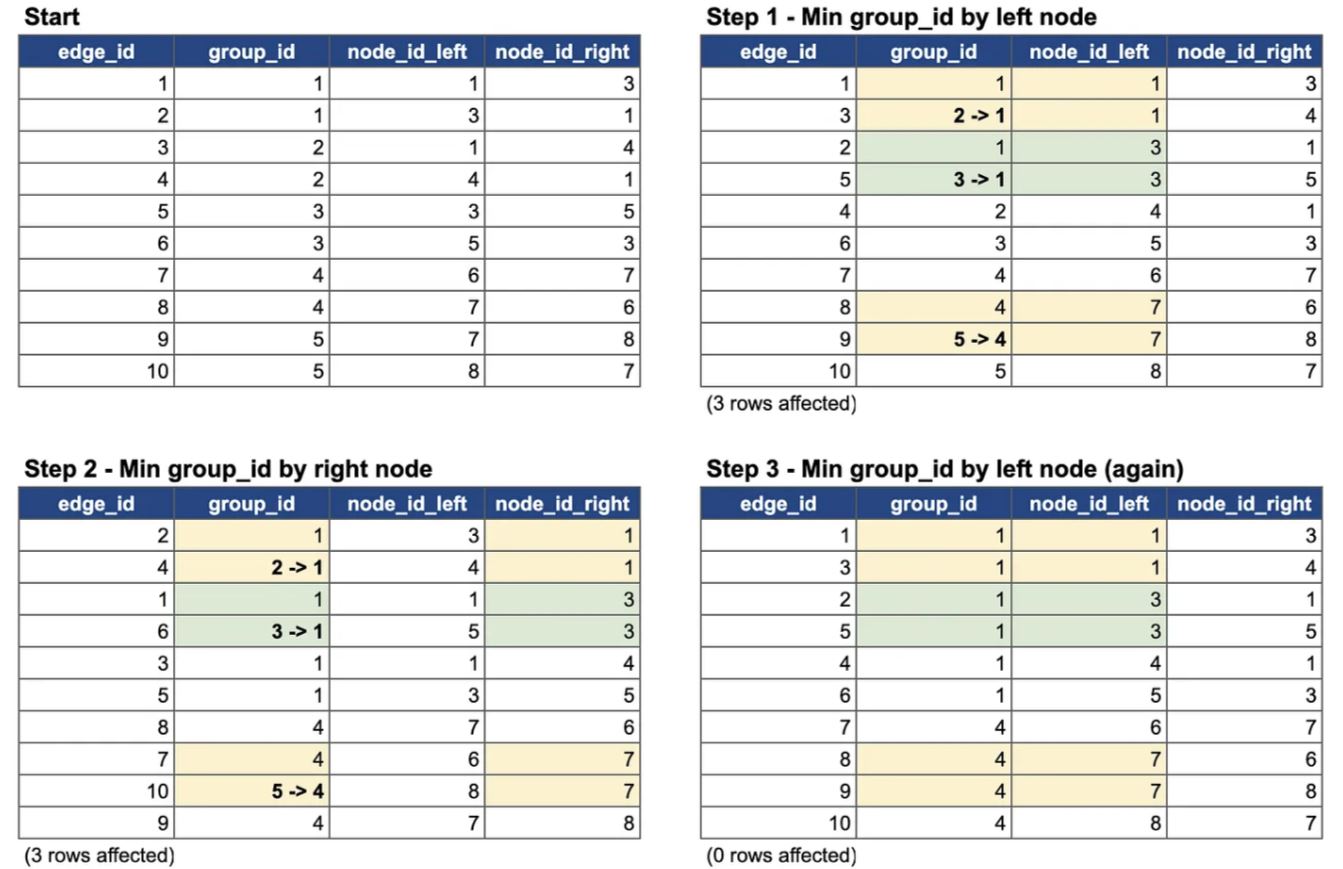
Повторяем эти действия в цикле до тех пор, пока все значения в столбцеhas_changedне станут равны нулю или цикл выполнится 14 раз (ограничение, которое устанавливаем самостоятельно. Опытным путём было установлено, что 14 итераций достаточно, чтобы найти все связи между узлами графа. Необходимость устанавливать определённое количество итераций для цикла обусловлено тем, что в dbt нельзя делать бесконечные циклы). Важно отметить, что после каждой итерации данные в таблицеgraph_eageобновляются.
В итоге все идентификаторы, которые относятся к одному пользователю получают один
group_id.Схематично действие этого макроса можно представить следующим образом:

ИсточникПосле срабатывания макроса
calc_glue, с помощью макросаgraph_glueполучаем уникальный идентификатор пользователяqid. Для этого группируем таблицуgraph_edgeпоnode_id_leftи отбираемmin(group_id) as qid. - 5.1 Сначала группируем данные из
-
graph_qid: с помощью этого макроса формируем таблицу-справочник, в которой каждому уникальному ключу, состоящему из(__link, __datetime, __id), соответствует уникальный идентификатор пользователяqidиз ранее созданной таблицыgraph_glue. Эту таблицу получаем путём объединения таблицыgraph_glueс таблицейgraph_lookup.
Последовательное выполнение этих макросов позволяет пошагово преобразовать исходные данные в графовую структуру и вычислить идентификаторы групп для каждого узла.
Зависимости
Подэтап graph_tuples зависит от таблиц, полученных на слое Link. Какие именно link-таблицы используются указывается в описании моделей графовой склейки glue_models в metadata.sql. Далее, каждая последующая модель зависит от результата выполнения предыдущей модели слоя.
Файл модели
Для слоя Graph создаётся 6 моделей, которые выполняются последовательно.
Правило наименования
Название моделей соответствует названиям макросав, которые их формируют:
graph_tuples.sqlgraph_lookup.sqlgraph_unique.sqlgraph_edge.sqlgraph_glue.sqlgraph_qid.sql
Правило создания
Создаётся по одному файлу модели на каждый подэтап слоя.
Примеры SQL запроса
(без макросов)
graph_tuples
{{ config(
materialized='table',
on_schema_change='fail'
)
}}
select
tuple(toLowCardinality(__link), __datetime, __id) as hash,
tuple(toLowCardinality('CrmUserHash'), toDateTime(0), CrmUserHash) as node_left
from {{ ref('link_events') }}
where nullIf(CrmUserHash, '') is not null
union all
select
tuple(toLowCardinality(__link), __datetime, __id) as hash,
tuple(toLowCardinality('YmClientHash'), toDateTime(0), YmClientHash) as node_left
from {{ ref('link_events') }}
where nullIf(YmClientHash, '') is not null
union all
<...>
И так для всех сущностей, помеченных в metadate.sql меткой glue: yes
graph_lookup
{{
config(
materialized='table',
order_by=('key_number')
)
}}
with all_keys as
(
select distinct hash as key_hash from {{ ref('graph_tuples') }}
union distinct select distinct node_left as key_hash from {{ ref('graph_tuples') }}
)
select *, row_number() over() as key_number from all_keys
graph_unique
{{
config(
materialized='table',
order_by=('key_hash')
)
}}
select * from {{ ref('graph_lookup') }}
graph_edge
{{
config(
materialized='table',
post_hook= {
'sql': 'insert into {{target.schema}}.graph_edge(node_id_left, node_id_right, group_id, has_changed)
select
node_id_right,
node_id_left,
group_id,
has_changed
from {{target.schema}}.graph_edge;'
}
)
}}
with join_left as (
select key_number as node_id_left,
node_left
from {{ ref('graph_tuples') }} x
join {{ ref('graph_unique') }} y on x.hash = y.key_hash
)
select node_id_left,
key_number as node_id_right,
node_id_left as group_id,
1 as has_changed
from join_left x
join {{ ref(graph_unique) }} y on x.node_left = y.key_hash
graph_glue
{{
config(
materialized='table',
order_by=('node_id_left'),
pre_hook="{{ datacraft.calc_graph() }}"
)
}}
select
node_id_left,
min(group_id) as qid
from {{ ref('graph_edge') }}
group by node_id_left
Код макроса `datacraft.calc_graph()` выглядит следующим образом:
{% macro calc_graph() %}
{# Запрос для обновления правой таблицы #}
{% set right_query %}
create or replace table {{ target.schema }}.graph_right engine=Log() as
with
min_group_id as (
select
node_id_left,
min(group_id) as min_group_id
from {{ target.schema }}.graph_edge
group by node_id_left
)
select
node_id_left,
node_id_right,
min_group_id as group_id,
min_group_id != e.group_id as has_changed
from {{ target.schema }}.graph_edge e
join min_group_id r on r.node_id_left = e.node_id_left
{% endset %}
{# Запрос для обновления левой таблицы #}
{% set left_query %}
create or replace table {{ target.schema }}.graph_edge engine=Log() as
with
min_group_id as (
select
node_id_right,
min(group_id) as min_group_id
from {{ target.schema }}.graph_right
group by node_id_right
)
select
node_id_left,
node_id_right,
min_group_id as group_id,
min_group_id != e.group_id as has_changed
from {{ target.schema }}.graph_right e
join min_group_id r on r.node_id_right = e.node_id_right
{% endset %}
{# Запрос для проверки наличия изменений #}
{% set check_changed %}
select
max(has_changed)
from {{ target.schema }}.graph_edge
{% endset %}
{# Если необходимо выполнить запросы #}
{% if execute %}
{% set ns = namespace(check_change=1) %}
{% for i in range(0, 14) %}
{{ log("Running iteration " ~ i) }}
{{ check_change }}
{# Проверяем, были ли изменения #}
{% if ns.check_change == 1 %}
{# Обновляем правую таблицу #}
{% do run_query(right_query) %}
{# Обновляем левую таблицу #}
{% do run_query(left_query) %}
{# Проверяем наличие изменений в данных #}
{% set ns.check_change = run_query(check_changed).rows[0][0] %}
{{ log('VALUE: ' ~ ns.check_change) }}
{% endif %}
{% endfor %}
{% endif %}
{% endmacro %}
graph_qid
{{
config(
materialized='table',
order_by=('__datetime', '__link', '__id'),
pre_hook="{{ datacraft.calc_graph() }}"
)
}}
select
toLowCardinality(tupleElement(key_hash, 1)) as __link,
tupleElement(key_hash, 2) as __datetime,
tupleElement(key_hash, 3) as __id,
qid
from {{ ref('graph_glue') }}
join {{ ref('graph_lookup') }} on key_number = node_id_left
Правила материализации
Для всех пайплайнов и на всех подшага данные материализуются как таблица - materialized='table'.
Автоматизация
Статус
В dataCraft Core слой графовой склейки полностью автоматизирован.
Макросы
datacraft.graph_tuples()datacraft.graph_lookup()datacraft.graph_unique()datacraft.graph_edge()datacraft.graph_glue()+datacraft.calc_glue()datacraft.graph_qid()+datacraft.calc_glue()
Подробнее про макросы слоя Graph.
IX. Attribution
Attribution или шаг атрибуции.
Зачем нужен
Атрибуция - это приписывание ценности за конверсию источникам трафика. Перед тем, как совершить конверсию (звонок, заказ, покупку), пользователь обычно совершает какие-то взаимодействия с компанией, например заходит на сайт. Эти взаимодействия называются событиями. У части событий мы можем определить маркетинговый источник, благодаря которому они произошли.
Чтобы оценить эффективность вложений в источник, необходимо знать сколько конверсий он принёс. Но не всегда можно однозначно определить источник. Чаще всего пользователь совершает несколько контактов с продуктом, прежде чем совершить покупку или другое целевое действие. Чтобы определить "главный" источник, принёсший конверсию, используют различные модели атрибуции. Модель атрибуции представляет собой правило или набор правил, по которым источнику присваивается ценность (степень его вклада в конверсию).
В зависимости от того, как именно мы распределим пользователей по источникам, мы получим разную картину происходящего. И сделаем разные выводы по эффективности источников трафика.
В dataCraft Core на слое Attribution как раз и происходит определение главного, согласно выбранной модели атрибуции, источника трафика и присвоение событиям (строкам в таблице) параметров относящихся к этому источнику.
Принцип работы
Слой Attribution состоит из 9 последовательных подэтапов. Для каждого подэтапа разработан свой макрос:
-
attr_prepare_with_qid: в этом макросе с помощьюLEFT JOINобъединяем full-таблицу с таблицейgraph_qid. Это необходимо, чтобы добавить к ней уникальный идентификатор пользователяqid. -
attr_create_events: на этом подэтапе определяем шаг воронки для каждой строки. Это реализуется с помощью конструкцииCASE WHEN. Для каждой строчки производится сопоставление значений из таблицыattr_prepare_with_qidc описанием шагов воронки в конфиге events. В этом конфиге мы указываем: название шага, к какому линку он относится и какое условие должно выполнятся, чтобы строку вattr_prepare_with_qidможно было отнести к этому шагу. Если условия, прописанные вCASE WHEN, выполняются, то строке присваивается порядковый номер шага воронки. Если событие не соответствует ни одному из шагов воронки, ему присваивается 0. Столбец с этими номерам получает название__priority. Также для каждой строчки указывается название шага. Эта колонка получает название__step.На этом шаге оставляем в таблице не все имеющиеся данные, а только
qid,__link,__priority,__id,__datetime, и__step. -
attr_add_row_number: на этом подэтапе добавляем к таблице, полученной наattr_create_events, порядковый номер строки__rnс помощью оконной функции, разбивая данные поqid, и сортируем данные по__datetime,__priority,__id. -
attr_find_new_period: с помощью этого макроса определяем когда у пользователя начался новый [период активности](# “это заранее определённый период взаимодействия клиента с продуктом. Если интервал между каждым взаимодействием (событием) меньше установленного периода, то эти действия клиента относятся к одному периоду активности, а если больше, то к разным. Период активности зависит от специфики бизнеса и устанавливается индивидуально.”). Как это происходит: в конфиге attributions, в разделеfunnel_stepsсодержится максимальный период (обычно в днях), который может быть между двумя последовательными событиями воронки. С помощью оконной функции для каждого пользователя вычисляем временную разницу между событиями. Если эта разность меньше установленного периода, то события считаются принадлежащими к одному периоду активности и в новую колонку__is_new_periodзаписываетсяFALSE, а если разность больше, то событие является началом нового периода активности и в колонке__is_new_periodзаписываетсяTRUE. Если период вmetadata.sqlне указан, то за период активности принимается период в 90 дней. -
attr_calculate_period_number: присваиваем каждому периоду свой порядковый номер__period_number. Все события (все строки) в рамках одного периода активности будут иметь одинаковый порядковый номер. Реализуется за счёт оконной функции с партицией поqidи сортировкой по__rn. Каждый раз, когда в рамках одногоqidвстречаетсяTRUEв колонке__is_new_period, порядковый номер периода увеличивается на единицу. -
attr_create_missed_steps: создаёт пропущенные шаги воронки. Это необходимо для упрощения следующих шагов, на которых уже непосредственно будет выполняться атрибуция. Добавляем пропущенные шаги только в том случае, если они были пропущены в рамках всей пользовательской истории взаимодействия с продуктом, а не в какой-то конкретный период активности. Например, в первый период активности пользователь прошёл шаги №1 и №2, потом долго (более установленного периода) не взаимодействовал с продуктом и в новый период активности сразу зашёл на шаг №3 и дальше пошёл по воронке. В таком случае для него не будут создаваться пропущенные шаги №1 и №2, так как он уже на них когда-то был. И наоборот, если пользователь был на всех шагах воронки со второго по последний, а на первом никогда не был, то для него создаётся фиктивный первый шаг с пометкойTRUEв специальной колонке__if_missed.Как это работает: для каждого
qidнаходим максимальный шагmax(__priority). Потом создаём дополнительную табличкуgenerate_all_prioritiesсо всеми шагами от первого до этого максимального с помощью функцийrangeиarrayJoin. Затем джойним её с основной таблицей, содержащей только реальные данные. Таким образом получаем таблицу, в которой появляются строки с пропущенными шагами и мы можем их чем-то заполнить, а в служебной колонке__if_missedпометить, что это пропущенные шаги.Принцип заполнения строк для пропущенных шагов: заполняем ближайшим не нулевым значением в рамках одного
qid, отсортированного по номеру шага, т.е. данными первого не пустого шага. Заполняем таким образом строки в колонках:__id,__datetimeи__period_number.Также на этом шаге добавляем новый номер строк
__rn. -
attr_join_to_attr_prepare_with_qid: после шагаattr_create_eventsмы работали с таблицами, содержащими только основные данные. На этом шаге объединяемattr_prepare_with_qidиattr_create_missed_steps, чтобы снова располагать полными набором полей.Также на этом шаге производится вычисление ранга для каждой модели в зависимости от ее приоритета. Список названий приоритетов для каждой модели указаны в конфиге attributions, а сами правила для каждого приоритета расписаны в конфиге event_segments. Помимо этого на этом шаге формируем новую колонку с источником трафика: для каждого пропущенного события указываем специальные значения, например 'Без веб сессии', 'Без установки'. Что конкретно указывать зависит от приоритета и того, что указано в конфиге events, содержащим описание шагов. Для реальных данных указываем просто их источник.
-
attr_model: на прошлом шаге мы вычисляли ранг для каждой строчки, теперь с помощью оконной функции в рамках одногоqidи одного периода активности__period_numberприсваиваем всем строчкам максимальный ранг (наиболее важный). Это нужно для подсчета числа целевых моделей (моделей с максимальным приоритетом) для каждого пользователя и периода. Каждый раз, когда ранг равен максимальному рангу, в вспомогательную колонку__{model_type}__rank_conditionзаписываетсяTRUE. Затем подсчитывается сколько былоTRUEзначений в рамкахqidи__period_number. Благодаря этим подсчётам получаем поле__{model_type}_target_count. Оно необходимо, чтобы разбить наши периоды на своеобразные подпериоды (модели) и внутри этих подпериодов для определённых полей (которые перечислены в конфиге attributions в разделеattributable_parameters) создать новые колонки, которые будут содержать во всех строчках значение из первой строчки подпериода. То есть каждому событию будут присвоен данные соответствующие главному источнику трафика (главному согласно выбранной модели атрибуции). -
attr_final_table: это последний шаг слояAttribution. На нём просто объединяем в одну таблицу результаты двух предыдущих макросов:attr_join_to_attr_prepare_with_qidиattr_model.
Зависимости
Первый подэтап attr_prepare_with_qid зависит от таблиц, полученных на слое Full, и от финальной таблицы слоя Graph - graph_qid. Далее, каждая последующая модель зависит от результата выполнения предыдущей модели слоя (или нескольких):
- 2.
attr_create_eventsот 1.attr_prepare_with_qid - 3.
attr_add_row_numberот 2.attr_create_events - 4.
attr_find_new_periodот 3.attr_add_row_number - 5.
attr_calculate_period_numberотattr_find_new_period - 6.
attr_create_missed_stepsот 5.attr_calculate_period_number - 7.
attr_join_to_attr_prepare_with_qidот 6.attr_create_missed_stepsи 1.attr_prepare_with_qid - 8.
attr_modelот 7.attr_join_to_attr_prepare_with_qid - 9.
attr_final_tableот 7.attr_join_to_attr_prepare_with_qidи 8.attr_model
Файл модели
Правило наименования
Чтобы сформировать название модели, к названию макроса добавляем название модели:
attr_{название модели атрибуции}_prepare_with_qidattr_{название модели атрибуции}_create_eventsattr_{название модели атрибуции}_add_row_numberattr_{название модели атрибуции}_find_new_periodattr_{название модели атрибуции}_calculate_period_numberattr_{название модели атрибуции}_create_missed_stepsattr_{название модели атрибуции}_join_to_attr_prepare_with_qidattr_{название модели атрибуции}_modelattr_{название модели атрибуции}_final_table
ВАЖНО! Название модели атрибуции, которое вы указываете в названии моделей, должно совпадать с названием модели атрибуции, которое указано в конфиге attributions. От этого зависит корректная работа макросов.
Правило создания
На каждом подэтапе создаётся столько моделей, сколько моделей вы хотите исследовать и задали. Например, если у вас только одна модель атрибуции, то на каждом подэтапе создаётся по одной модели, если две, то две модели и так далее.
Примеры SQL запросов
(приводятся примеры запросов как бы они выглядели без использования макросов)
attr_prepare_with_qid:
{{
config(
materialized='table',
order_by=('qid', '__datetime','__link','__id')
)
}}
select
y.qid, x.*
from {{ ref('full_events') }} as x
left join {{ ref('graph_qid') }} as y
using (__datetime,__link, __id)
attr_create_events
{{
config(
materialized='table',
order_by=('qid', '__datetime','__link','__id')
)
}}
select
qid,
__link,
CASE
WHEN __link = 'VisitStat' and osName = 'web' THEN 1
WHEN __link = 'AppInstallStat' and installs >= 1 THEN 2
WHEN __link = 'AppSessionStat' and sessions >= 1 THEN 3
WHEN __link = 'AppDeeplinkStat' THEN 3
WHEN __link = 'AppEventStat' and screenView >= 1 THEN 4
ELSE 0
END as __priority,
__id,
__datetime,
toLowCardinality(CASE
WHEN __link = 'VisitStat' THEN 'visits_step'
WHEN __link = 'AppInstallStat' THEN 'install_step'
WHEN __link = 'AppSessionStat' THEN 'app_visits_step'
WHEN __link = 'AppDeeplinkStat' THEN 'app_visits_step'
WHEN __link = 'AppEventStat' THEN 'event_step'
END) as __step
from {{ ref('attr_myfirstfunnel_prepare_with_qid') }}
attr_add_row_number
{{
config(
materialized='table',
order_by=('qid', '__datetime', '__link', '__id')
)
}}
select
*,
row_number() over (partition by qid order by __datetime, __priority, __id) AS __rn
from {{ ref('attr_myfirstfunnel_create_events') }}
attr_find_new_period
{{
config(
materialized='table',
order_by=('qid', '__datetime', '__link', '__id')
)
}}
with prep_new_period as (
select *,
max(case when __priority in [1, 2, 3, 4] then __datetime else null end)
over (partition by qid order by __rn rows between unbounded preceding and 1 preceding) as prep_new_period
from {{ ref('attr_myfirstfunnel_add_row_number') }}
)
select
qid,
__link,
__priority,
__id,
__datetime,
__rn,
__step,
CASE
WHEN __link = 'VisitStat' and toDate(__datetime) - toDate(prep_new_period) < 90 THEN false
WHEN __link = 'AppInstallStat' and toDate(__datetime) - toDate(prep_new_period) < 30 THEN false
WHEN __link = 'AppSessionStat' and toDate(__datetime) - toDate(prep_new_period) < 30 THEN false
WHEN __link = 'AppDeeplinkStat' and toDate(__datetime) - toDate(prep_new_period) < 30 THEN false
WHEN __link = 'AppEventStat' and toDate(__datetime) - toDate(prep_new_period) < 7 THEN false
ELSE true
END as __is_new_period
from prep_new_period
attr_calculate_period_number
{{
config(
materialized='table',
order_by=('qid', '__datetime', '__link', '__id')
)
}}
select *,
sum(toInt32(__is_new_period)) over (partition by qid order by __rn) AS __period_number
from {{ ref('attr_myfirstfunnel_find_new_period') }}
attr_create_missed_steps
{{
config(
materialized='table',
order_by=('qid', '__datetime','__link','__id')
)
}}
with calc_max_priority as (
select
qid,
__link,
__id,
__datetime,
__rn,
__priority,
__period_number,
__step,
max(__priority) over(partition by qid) as max_priority
from {{ ref('attr_myfirstfunnel_calculate_period_number') }}
),
generate_all_priorities as (
select
distinct qid, __link,
arrayJoin(range(1, assumeNotNull(max_priority) + 1)) as gen_priority
from calc_max_priority
),
final as (
select
first_value(__id) OVER (PARTITION BY qid ORDER BY gen_priority ROWS BETWEEN current row AND UNBOUNDED FOLLOWING ) as __id,
gen_priority as __priority,
qid, __link,
first_value(__datetime) OVER (PARTITION BY qid ORDER BY gen_priority ROWS BETWEEN current row AND UNBOUNDED FOLLOWING ) as __datetime,
first_value(__period_number) OVER (PARTITION BY qid ORDER BY gen_priority ROWS BETWEEN current row AND UNBOUNDED FOLLOWING ) as __period_number,
case when calc_max_priority.qid = 0 then true else false end as __if_missed,
__step
from generate_all_priorities
left join calc_max_priority
on generate_all_priorities.qid = calc_max_priority.qid and
generate_all_priorities.gen_priority = calc_max_priority.__priority
)
select
qid, __link, __id,
__priority, __datetime,
__period_number,
__if_missed,__step,
row_number() over (partition by qid order by __datetime, __priority, __id) AS __rn
from final
attr_join_to_attr_prepare_with_qid
{{
config(
materialized='table',
order_by=('qid', '__period_number', '__datetime', '__priority', '__id')
)
}}
select
y.__period_number as __period_number,
y.__if_missed as __if_missed,
y.__priority as __priority,
y.__step as __step,
x.*EXCEPT(adSourceDirty),
CASE
WHEN LENGTH (adSourceDirty) < 2 THEN 1
WHEN match(adSourceDirty, 'Органическая установка') THEN 2
WHEN __priority = 4 and not __if_missed = 1 THEN 3
WHEN __priority = 3 and not __if_missed = 1 THEN 4
WHEN __priority = 2 and not __if_missed = 1 THEN 5
WHEN __priority = 1 and not __if_missed = 1 THEN 6
ELSE 0
END as __last_click_rank,
CASE
WHEN __priority = 3 and not __if_missed = 1 THEN 1
WHEN __priority = 2 and not __if_missed = 1 THEN 2
WHEN __priority = 1 and not __if_missed = 1 THEN 3
ELSE 0
END as __first_click_rank,
CASE
WHEN __if_missed and __priority = 1 THEN '[Без веб сессии]'
WHEN __if_missed and __priority = 2 THEN '[Без установки]'
WHEN __if_missed and __priority = 3 THEN '[Без апп сессии]'
WHEN __if_missed and __priority = 4 THEN ''
ELSE adSourceDirty
END as adSourceDirty
from {{ ref('attr_myfirstfunnel_prepare_with_qid') }} AS x
join {{ ref('attr_myfirstfunnel_create_missed_steps') }} AS y
using (qid, __datetime, __link, __id)
attr_model
{{
config(
materialized='table',
order_by = ('qid', '__datetime', '__id')
)
}}
with
max_last_click_rank as (
select *
,max(__last_click_rank) over(partition by qid, __period_number order by __datetime, __priority, __id) as __max_last_click_rank
,max(__first_click_rank) over(partition by qid, __period_number order by __datetime, __priority, __id) as __max_first_click_rank
from {{ ref('attr_myfirstfunnel_join_to_attr_prepare_with_qid') }}
),
target_count as (
select *
, __last_click_rank = __max_last_click_rank as __last_click__rank_condition
, sum(case when __last_click__rank_condition then 1 else 0 end) over(partition
by qid, __period_number order by __datetime, __priority, __id) as
__last_click__target_count
, __first_click_rank = __max_first_click_rank as __first_click__rank_condition
, sum(case when __first_click__rank_condition then 1 else 0 end) over(partition
by qid, __period_number order by __datetime, __priority, __id) as
__first_click__target_count
from max_last_click_rank
)
SELECT qid, __datetime, __id, __priority,`__if_missed`, __link, __period_number
, first_value(utmSource) over(partition by qid, __period_number, __last_click__target_count order by __datetime, __priority, __id) as __myfirstfunnel_last_click_utmSource
, first_value(utmMedium) over(partition by qid, __period_number, __last_click__target_count order by __datetime, __priority, __id) as __myfirstfunnel_last_click_utmMedium
, first_value(utmCampaign) over(partition by qid, __period_number, __last_click__target_count order by __datetime, __priority, __id) as __myfirstfunnel_last_click_utmCampaign
, first_value(utmTerm) over(partition by qid, __period_number, __last_click__target_count order by __datetime, __priority, __id) as __myfirstfunnel_last_click_utmTerm
, first_value(utmContent) over(partition by qid, __period_number, __last_click__target_count order by __datetime, __priority, __id) as __myfirstfunnel_last_click_utmContent
, first_value(adSourceDirty) over(partition by qid, __period_number, __last_click__target_count order by __datetime, __priority, __id) as __myfirstfunnel_last_click_adSourceDirty
<...>
FROM target_count
attr_final_table
{{
config(
materialized = 'table',
order_by = ('__datetime')
)
}}
with out as (
select * except(_dbt_source_relation)
from {{ ref('ttr_myfirstfunnel_join_to_attr_prepare_with_qid') }}
join {{ ref(attr_myfirstfunnel_model) }}
using (qid, __datetime, __id, __link, __period_number, __if_missed,
__priority)
)
select * from out
Правила материализации
На всех шагах слоя используем следующий тип материализации: materialized = 'table'.
Автоматизация
Статус
Слой полностью автоматизирован.
Макросы
datacraft.attr_prepare_with_qid()datacraft.attr_create_events()datacraft.attr_add_row_number()datacraft.attr_find_new_period()datacraft.attr_calculate_period_number()datacraft.attr_create_missed_steps()datacraft.attr_join_to_attr_prepare_with_qid()datacraft.attr_model()datacraft.attr_final_table()
Подробнее про макросы слоя Attribution.
X. Dataset
Dataset или датасет - последний шаг обработки данных
Зачем нужен
На этом этапе формируются датасеты, на основе которых строятся отчёты в BI-системе. В них попадают не все данные, а только необходимые для построения отчёта.
Принцип работы
Если никаких дополнительных преобразований не требуется, датасет строится с помощью макроса, который фильтрует таблицу полученную на слое Full или на Attribution (если производилась атрибуция) и отбирает только необходимы поля и строки.
Какую таблицу брать за основу (full или attr) макрос определяет по пайплайну. Данные из каких источников включать прописывается в конфиге datasets, а данные по каждому источнику содержатся в конфиге datasources. На основе этих данных фильтруется исходная таблица. В финальный датасет попадают только те данные, которые относятся к указанным источнику, аккаунту и шаблону.
В один датасет могут входить несколько таблиц, описанных в datasets. Какие конкретно таблицы входят передаётся в качестве аргумента макроса.
Если же необходимы какие-то специфические преобразования или расчёты, то запрос пишется вручную конкретно под задачу.
Зависимости
Зависит либо от full-таблиц, либо от таблиц слоя Attribution.
Файл модели
Правило наименования
dataset_{название датасета}
Правило создания
Создаётся столько моделей, сколько необходимо.
Пример SQL запроса
(без использования макроса)
{{
config(
materialized = 'table',
order_by = ('__datetime')
)
}}
SELECT * FROM (
(
select toLowCardinality('full_datestat') as _dbt_source_relation,
toString("None") as None ,
toDate("__date") as __date ,
toString("reportType") as reportType ,
toString("accountName") as accountName ,
toString("__table_name") as __table_name ,
toString("adSourceDirty") as adSourceDirty ,
<...>
toString('') as __myfirstfunnel_first_click_utmTerm ,
toString('') as __myfirstfunnel_first_click_utmContent ,
toString('') as __myfirstfunnel_first_click_adSourceDirty
from {{ ref('full_datestat') }}
)
union all
(
select toLowCardinality('attr_myfirstfunnel_final_table') as _dbt_source_relation,
toString("None") as None ,
toDate("__date") as __date ,
toString('') as reportType ,
toString("accountName") as accountName ,
toString("__table_name") as __table_name ,
toString("adSourceDirty") as adSourceDirty ,
<...>
toString("__myfirstfunnel_first_click_utmTerm") as __myfirstfunnel_first_click_utmTerm ,
toString("__myfirstfunnel_first_click_utmContent") as __myfirstfunnel_first_click_utmContent ,
toString("__myfirstfunnel_first_click_adSourceDirty") as __myfirstfunnel_first_click_adSourceDirty
from {{ ref('attr_myfirstfunnel_final_table') }}
)
)
WHERE
splitByChar('_', __table_name)[4] = 'yd'
and
splitByChar('_', __table_name)[4] = 'testaccount'
and
splitByChar('_', __table_name)[4] = 'default'
UNION ALL
<...>
Правила материализации
Используется materialized = 'table'.
Автоматизация
Статус
Слой полностью автоматизирован.
Макросы
datacraft.create_dataset()
Подробнее про макрос creat_dataset.